{kind=link}

Figure 1: A stream of a's and b's in a sample text
Improvements in the field of data compression up until the late 1970's were chiefly directed towards creating better methodologies for Huffman Coding. In order to obtain the necessary frequencies of symbols in the data to be compressed, these methods either had to rely on the ability to predict such occurrences or would require that the text be read in beforehand.
In 1977, two Israeli information theorists, Abraham Lempel and Jacob Ziv, introduced a radically different way of compressing data - one which would avoid the uncertainty of making predictions or the wastefulness of pre-reading data. LZ77 and LZ78, two dictionary-based data compression techniques described by these two researchers, provided a whole new way of viewing the world of data compression.
Table of ContentsThe highly innovative LZ77 and LZ78 methods, although usually referred to as the singular Lempel-Ziv (LZ) or Ziv-Lempel method, are in fact considerably different. Both algorithms are based on the principle of storing pointers to the data. The pointers make references to phrases which have made previous appearances. In both cases, encoding proceeds "on the fly," so that as symbols are read in, more and more phrases are stored (in that respect, the LZ compression techniques are a bit like a suffix trie). It is important, however, to note that LZ77 and LZ78 are distinct. The method which will be discussed here, and which will later be treated as "the" Lempel-Ziv compression technique, is in reality the latter of the two.
Lempel and Ziv's compression techniques of '77 and '78 gave rise to a series of variants which form part of the LZ family. The variants are essentially identical to the method from which they originate (either LZ77 or LZ78). Variations have to do with factors such as establishing how many bits to use for certain boundaries. A list of these coding algorithms is provided below (Table 1).
| LZ77 Variants | LZR | LZSS | LZB | LZH | |||
|---|---|---|---|---|---|---|---|
| LZ78 Variants | LZW | LZC | LZT | LZMW | LZJ | LZFG | |
As an example, the zip and unzip methods use the LZH techique. UNIX compress methods, on the other hand, belong to the LZW and LZC classes.
A question that would naturally arise at this point is "Why so many variants?" The answer is...patents. Disputes over patenting have actually slowed down the evolutionary progress of the LZ method.
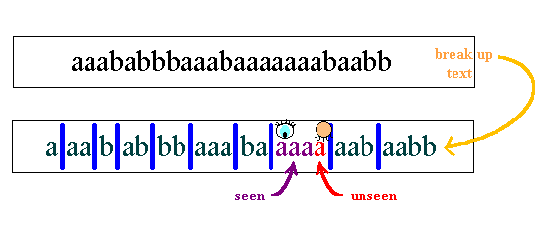
Table of ContentsTo illustrate the LZ compression technique, we take a simple alphabet containing only two letters, a and b, and create a sample stream of text. An example of such a stream is shown below (Figure 1):
Rule: Separate this stream of characters into pieces of text so that the shortest piece of data is the string of characters that we have not seen so far.
According to the above rule, we see that the first piece of our sample text is a. The second piece must then be aa. If we go on like this, we obtain the breakdown of data illustrated in Figure 2:
Before compression, the pieces of text obtained in the breaking-down process must be indexed from 1 to n, as in Figure 3 below:
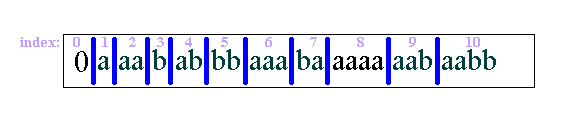
These indices are used to number the pieces of data. The empty string (start of text) has index 0. The piece indexed by 1 is a. Thus a, together with the initial string, must be numbered Oa. String 2, aa, will be numbered 1a, because it contains a, whose index is 1, and the new character a. In this way, we proceed to number all the pieces in terms of those that came before them. See Figure 4 for an illustration of this technique:
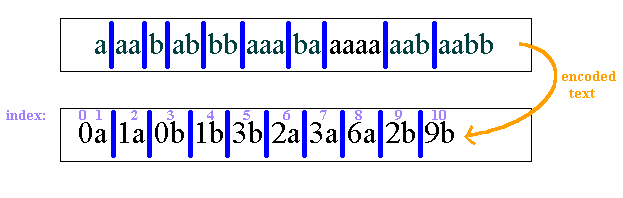
As we can see, this process of renaming pieces of text starts to pay off. Small integers replace what were once long strings of characters. We can now throw away our old stream of text and send the encoded information to the receiver, as will be discussed in the next section.
Table of ContentsNow, we wish to calculate the number of bits needed to represent this coded information. As we have seen before, each piece of text is composed of an integer and a letter from our alphabet.
The number of bits needed to represent each integer with index n is at most equal to the number of bits needed to represent the (n-1)th index. For example, the number of bits needed to represent 6 in piece 8 is equal to 3, because it takes three bits to express 7 (the (n-1)th index) in binary.
Every character will occupy 8 bits because it will be represented in US ASCII format. Figure 5 illustrates this thinking process:
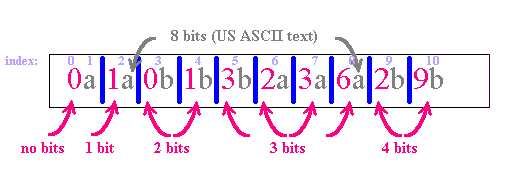
One of the advantages of Lempel-Ziv compression is that in a long string of text, the number of bits needed to transmit the coded information is peanuts compared to the actual length of the text. This becomes apparent when we use, for example, 12 bits to transmit the code 2b instead of 24 bits (8 + 8 + 8) needed for the actual text aab.
Property: On text files with independent random symbols occuring with probabilities p1, p2, p3,...,pk, the expected number of bits needed per symbol tends to the entropy:
The expected number of bits per symbol, in any compression method and using the random independent symbol model, is at least equal to the entropy (based on information-theoretical considerations). The Huffman code achieves this, but it must have knowledge of the probabilities. Interestingly, the Lempel-Ziv code performs equally well (on large input files), without that knowledge. It is thus truly adaptive and asymptotically optimal.
Table of ContentsSince the receiver knows exactly where the boundaries are, there is no problem in reconstructing the stream of text.
It is preferrable to decompress the file in one pass; otherwise, we will encounter a problem with temporary storage. This feature allows you to process many megs of information at one time.
Given the code, the receiver constructs a trie "on the fly". This must be identical to the trie contructed by the sender. It is illustrated below (Figure 6):
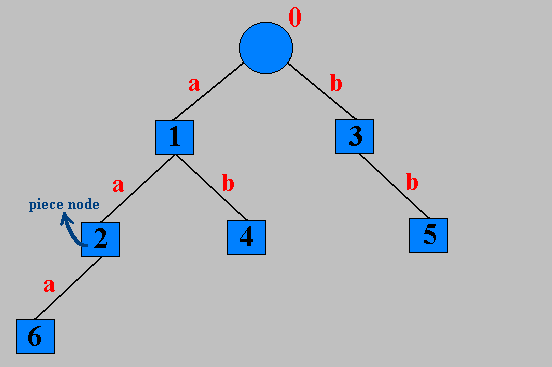
Note: To find the contents of a particular piece, trace the path from the node to the root. For example, piece 2 will contain 1a.
The structure shown above is called a digital search tree and is part of the trie family. It is different from the standard trie because the internal nodes do not live only in the leaves.
Table of ContentsThe following applet will compress and decompress text using LZ78. To crunch text, just type it into the upper window and it should appear in the lower window. If your machine refuses to do so automatically, you can click on Update to force it to crunch the text. Uncrunching text is similar, just click on the uncrunch box and type tokens into the lower window.
The Binary button converts text into a compressed form. Do note that the vertical bars wouldn't appear normally, but are just there to improve legibility. Also, since Java doesn't do USASCII, the applet translates characters into numbers using some inherent Java scheme.
Detailed comments are also available.
For the source, click here.
Table of Contents
| Lempel-Ziv-Welch Algorithm |
Dr. Ze-Nian Li's lecture notes on the popular LZW variant of the LZ data compression method, including algorithms for LZW compression and decompression, from Simon Fraser University. |
| CIS 650: Information Storage and Retrieval: Compression |
LZW compression, decompression, implementation issues, and algorithms by Prof. Gary Perlman, of Ohio State University. |
| LZW and GIF explained ---- Steve Blackstock |
A document from The PC Games Programmers Encylopedia 1.0, describing the basics of the Lempel-Ziv-Welch compression algorithm, by Steve Blackstock. |
| Data Compression: OTHER ADAPTIVE METHODS |
Prof. Dan Hirschberg's (University of California, Irvine) notes illustrating and explaining the LZ coding technique. |
| History of the LZW patent |
A document describing research done on the LZW patent by Ron Baalke, of NASA. |
| LZW Patent text |
The text of the LZW patent held by Welch. |
| The Redundancy of the Ziv-Lempel Algorithm for Memoryless Sources |
A discussion of the redundancy of the Lempel-Ziv algorithm by Tjalling Tjalkens. |
| A sample problem on LZ Data Compression (Problem B) |
An exercise involving the Lempel-Ziv compression and decompression methods, including explanations, by Aaron D. Wyner, from the IEEE Information Theory Society. |
| Part IV: Data Compression |
David Cyganski, of the Worceseter Polytechnic Institute, presents here another illustrative set of notes on Lempel-Ziv encoding. |
| LZW compression |
A summary on LZW Compression by Christopher Chisholm, from the Curtin School of Computing. |
1. Bell, T.C, Cleary, J.G., Witten, I.H. Text Compression. Prentice Hall, 1990.
2. Nelson, M. The Data Compression Book. MIT PUBL Inc, 1992
3. Lynch, Thomas J. Data Compression Techniques and Applications. Belmont California: Lifetime Learning Publications, 1988.
4. Storer, James A. Data Compression: Methods and Theory. Rockville, Maryland: Computer Science Press, 1988.
This web page was created by
Patricia and Hala found the links to related materials, found the references, typed the document, and drew the pictures using Microsoft Paint to supplement the text. Patrick programmed and documented the java applet. The text is based on class notes taken by all of us.
"SHMART...KILL KILL!!! Call me Abbie!"
Last updated March 27, 1997 by Patty Bejerman & Hala Khan.{kind=link}